With the release of HCX 4.8 comes in my opinion one of the biggest new features released since Network Extension High Availability went IA in 4.3.
In previous versions for any given Compute Profile pair, while it was possible to deploy more than one Service Mesh, only the first one would be used. I previously blogged about this here. This means that for large scale RAV migrations, whilst up to 200 VMs per Service Mesh could be replicated, only one VM switchover at a time would occur. Effectively this meant that the 200 VMs would be sent into a funnel and only a single VM would be live migrated at a time. There is a lot going on with RAV switchovers and the switchover event could be time consuming, taking anywhere from a few minutes to an hour depending on the size of the VM and its churn rate (plus many other factors).
In the release notes of HCX 4.8 there is the following statement:
Single-Cluster Multi-Mesh Scale Out (Selectable Mesh)
We’ve improved scaling options in HCX 4.8 by removing the notion of clusters as the limiting factor for HCX migration architectures. Single and multi-cluster architectures can now leverage multiple meshes to scale transfer beyond the single IX transfer limitations. The new scale out patterns help mitigate the concurrency limits for Replication Assisted vMotion and HCX vMotion.
You can now explicitly select the Service Mesh during a migration operation. You might choose a specific Service Mesh to use for a migration based on the parameters or resources associated with that Service Mesh configuration, or to manually load balance operations across the cluster. If no Service Mesh is selected, HCX determines the Service Mesh to use for the migration. To migrate workloads using HCX, see Migrating Virtual Machines with HCX.
Note:
A scaled-out HCX 4.8 deployment increases the potential for exceeding vSphere maximums for vMotion migration limits. Please observe all vSphere migration maximums when increasing HCX scale within a cluster.
I’ve highlighted the important final statement, which I’ll mention toward the end of this post.
And a screenshot of the option in the UI:
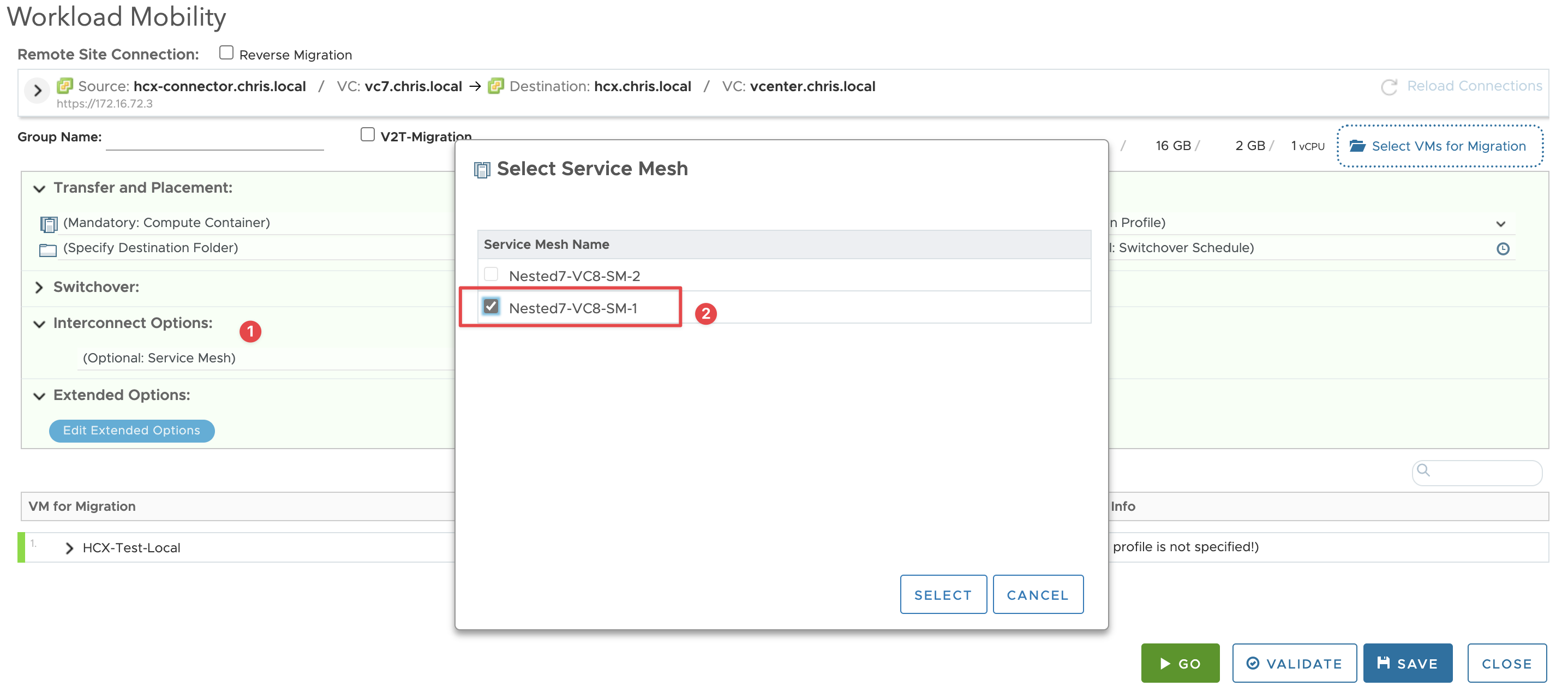
As stated, this also works for Bulk Migration where you could split your migrations up across IX appliances to increase migration velocity as each has its own throughput limitations as documented on VMware Config Max. You can also concurrently vMotion VMs if you only had a small handful to move, and you wanted them to move quicker than waiting for each migration operation to complete.
For the purposes of this article, I wanted to focus on RAV however, and to some extend cover bulk migration too. Currently you are able to move 200 VMs in a RAV migration wave*, with the following documented contraints:
- 1 concurrent switchover (the vMotion part of RAV)
- Up to 2 Gbps throughput limitation on the IX appliance (due to encryption overheads)
*My golden rule with HCX is that just because you can, doesn’t mean you should!
Up to 2 Gbps, because it largely depends on the environment that the IX appliances are deployed into. They perform in flight datapath encryption which is done in software by the host CPU; if you have a fast CPU and a good V to P ratio, you may see closer to the 2 Gbps throughput figure, but for busier environments with slower CPU clockspeed, this throughput would be reduced. There are other factors to consider, such as disk speed/IO, network underlay, etc, etc. There are many factors which affects the throughput, which is why it is largely undocumented as it would be an impossible task to cater for every environment.
Let us say as an example that there are 200 VMs in scope to migrate in a single migration wave from a legacy source cluster to a new VCF 5.1 cluster. The mean VM disk size is 500GB. They are on an old legacy environment which is resource constrained and has slow CPUs and physical network infrastructure which is need of replacement. Due to this, the average IX to IX throughput is limited to ~1 Gbps. Using one of many online file copy calculators, just to move the initial data would be over 9 days. Each of the source VMs is in use and as such, the data on the VM is also changing which means that changed data also needs to be replicated, then there is overhead, retransmits etc. You could easily add on another 2-3 days before the entire group is ready for switchover. Then when the first switchover occurs, a vMotion is initiated and the active RAM of the VM is also moved, contenting with the HBR aspect of RAV. Once all VMs have completed their base sync, it’s going to take quite a bit of time to live migrate the whole wave 1 by 1.
There are a huge amount of assumptions in this example, and with most migrations 500GB as a mean disk size is overexaggerated, but not beyond the realms of possibility with our largest customers. Ordinarily I would advise the use of Service Mesh scale out feature by deploying additional source and/or destination clusters. Realistically, this is not always possible, and in some of the largest deployments I have seen, Service Mesh deployment is already optimal. In these situations, breaking down the waves into smaller batches greatly increases the migration velocity and also reduces the chances of migration failures.
With the release of HCX 4.8, it’s possible to deploy additional Service Meshes for a single cluster to cluster pair. Using the above example, you can now deploy 4x Service Meshes, and break the waves up as follows:
- 50 VMs on Service Mesh 1
- 50 VMs on Service Mesh 2
- 50 VMs on Service Mesh 3
- 50 VMs on Service Mesh 4
With each IX being limited by the source environment to 1 Gbps, this new deployment quadruples (4x!) the throughput to 4 Gbps (if the rest of the environment can keep up!). In addition, you also benefit from having 4x concurrent switchover events.
Rather than 9 days, the initial sync with the new deployment architecture would be complete in just over 2 days (55.56 hours rather than 222.2 hours). And 1x VM from each of the four Service Meshes would switchover which gives 4x concurrent switchovers.
Again, I must stress that the above example is entirely theoretical, but I hope that it shows what this new feature is capable of providing.
Finally, I just wanted to mention that HCX vMotion is costed in the same that a Cross vCenter vMotion is:
- Source & Destinations ESXi hosts can handle two concurrent vMotions.
- Source & Destinations datastores hosts can process eight concurrent vMotions.
- Day to day cluster operations such as DRS, vCenter tasks etc. could be a factor in busier environments.
As a recommendation, you should not deploy more Service Meshes than what you require because you don’t want to interfere with regular operations in the source and destination environments, then there’s the additional CPU and resource overhead by each IX. If you want to benefit, maybe start with two Service Meshes in smaller environments, effectively doubling throughput and switchover concurrency, and four for larger environments with > 6 hosts (this is not a VMW recommendation, just my personal opinion).
Finally, I just wanted to thank all the members in the HCX/NSBU team who have made this possible, as it is going to be well received especially by customers with larger migrations to accomplish.
Thanks for reading.
1 thought on “What’s new in HCX 4.8? Selectable Service Mesh!”