VMware Cloud Disaster Recovery (VCDR) is a relatively new product, certainly compared to Site Recovery Manager (SRM) which has been around since 2007; to put that into perspective, vSphere 5.0 didn’t go GA until 2011. The basic premise of the products are similar in that we configure protected sites, recovery sites, as well as folder mapping, resource pool mapping, network mapping and so on to allow us to execute Recovery Plans into our recovery environment. Which begs the question – why have two products which do the same thing? The answer is fairly straight forward – they don’t. From a very high level it may appear so but once we start scratching the surface we can see that whilst the two products are broadly similar, there are some big differences, ones which will ultimately decide on which product you would use to meet your requirements.
For VCDR to make a little more sense, I need to cover a little it of history. When SRM was released, the concept of VMware in the cloud and hyperscalers didn’t exist, certainly not as it does today. The less said about vCloud Air the better so I won’t cover that!
Cast your mind back to the pre-cloud era, and for many, still how you operate your virtual environment today. For the sake of simplicity, imagine we have two (private/on-prem) data centres, one which hosts our primary environment including production workloads. And a second DC, geographically separate from the primary, connected together usually in the way of an MPLS circuit provided by a service provider. In the primary site we would have a lots of servers running ESXi, some networking equipment, and some storage. This storage comprised of one or more controllers and some disk shelves connected together in their own private network, aka as a Storage Area Network. SANs (they still exist!) would then connect to the hosts using either Fibre Channel via Fibre Channel switches (less common these days) or using iSCSI over an IP network. Within the SAN we would carve up storage and present it to the vSphere environment using LUNs (Logical Unit Numbers). These LUNs would be mounted as VMFS datastores on our hosts. They provided nearly all of the storage that our workload VMs would consume. In the second DC, we would have a similar environment, with the same vendor providing the SAN infrastructure. Forgive my terrible diagram!
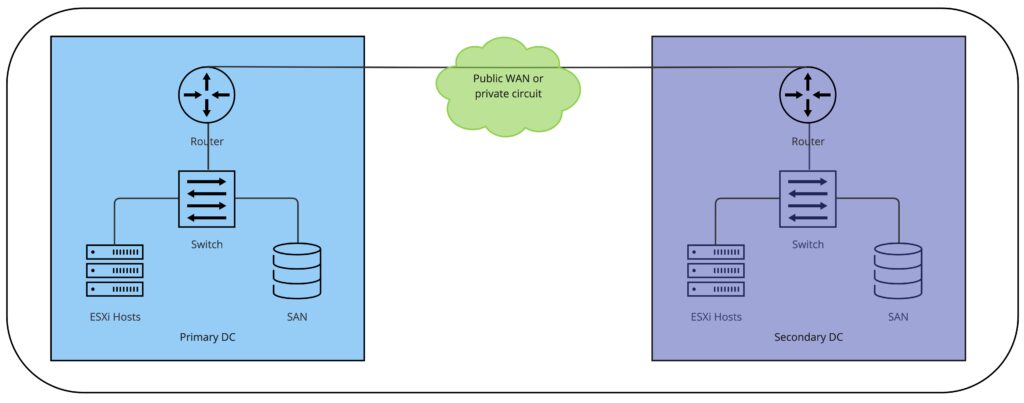
SRM would then be installed and we’d make use of Storage Replication Adaptors (SRAs) so that SRM could talk to the SANs, and the arrays would do the heavy shifting of data to the secondary DC on any LUNs which contained the VMs we want to protect. SRM would then be configured to protect VMs and from there we create Recovery Plans. In the event of a total disaster at the primary site, we can bring workloads online in the recovery environment and SRM would orchestrate the process. It worked, and it worked really well (apart from some SRA nuances which I won’t cover here but any seasoned SRM administrator will know what I mean). There is also a vSphere Replication appliance which replicated data directly from the hosts, rather than relying on the storage arrays. This decoupled vendor lock in and having to use SRAs, and it allows us to replicate to software defined storage such as vSAN. Both options allow us to replicate protected workloads from a protected site to a recovery site.
We may have 20TB worth of storage in the primary site, and an enterprise architect after discussing DR with the business would specify 10TB of storage in the recovery site, so that in the event of an outage in the primary, using SRM we could fail over to the recovery site and get the most critical applications up and running again. It is not uncommon to have a recovery environment which is smaller than the protected, and there are also solutions where they mirror one another. As time moves forward, so does our data consumption. More and more applications are developed or considered critical, so we must add storage in our primary data centre as well as our secondary. This would involve a phone call to the storage vendor, a lot of change requests, and eventually racking and stacking new disk shelves, or replacing disks with higher capacity ones. Or even an entirely new SAN. This has worked reasonably well since its release, and it still does today.
As time progressed, technology advances and changes. Hyper Converged Infrastructure has become more commonplace, and VMC on AWS has grown massively. There are now other public cloud options too, such as Microsoft’s AVS, Google’s GCVE, Oracle Cloud, and others. Rather than having storage arrays, we’ve moved the storage onto the hosts themselves and we leverage high speed switching infrastructure which allow us to create software defined SANs, such as vSAN. In today’s public cloud world, if we require more storage we usually require more hosts. This costs quite a bit of money, especially if it’s in an otherwise unused recovery environment which must be online for SRM to function. There may also be licensing implications too. Sure, there are now other storage options on the table such as FSx or Flex, however they’re usually flash based and whilst not as expensive as a new node, they are still cost prohibitive compared to adding a disk shelf to a SAN. Unfortunately, we are unable to drive to a public cloud data centre with a SAN and ask them to install it next to our hosts, we’d be laughed away.
The other issue for SRM is that we have a limited number of recovery options available to us. It’s designed to recover VMs, and recover them quickly into our recovery environment and it does it very well (if configured correctly – and tested!). Consider that our company has suffered a ransomware attack, and after some investigation we know the original compromise happened 3 months ago. SRM cannot help here, as it has a limited amount of recovery points. We can configure multiple point in time snapshots, but this consumes additional storage, and yes you’ve guessed it, this costs more money because we require more nodes to provide the storage. Plus, it only works for the previous week or so. Outside of this window, we need to look at our backup products for recovery options.
In short, SRM has a number of issues in a public cloud world:
- Our recovery environment must be online
- It’s expensive, due to the cost of public cloud storage
- Limited ransomware protection
How does VCDR overcome the above? And by doing so, does it make it better than SRM?
The first piece of the puzzle is the management layer. With SRM, we require both protected and recovery appliances to be online to configure protection, and we require the recovery appliance online to invoke recovery if the primary site is lost. This means hosts, networking, vCenter, and in public clouds it means NSX too. If we are using SRM to replicate to a VMC on AWS (VMC/A) environment as an example, we must have a minimum 2 node SDDC deployed. Depending on the host type, this might not give you much storage for the replicated VMs. VCDR decouples the management layer from vSphere, which means we do not require the recovery environment to be online. More on this later.
Next up comes the storage. SRM requires a datastore to replicate to. In VMC/A, this is provided by the WorkloadDatastore backed by vSAN. I’ve already alluded that fact that this can be considerably expensive, especially as we can’t really use the hosts as their resources would be required in the event of a failover. With VCDR, we replicate into something called the Scale-out Cloud File System (SCFS). The SCFS does not require an SDDC to be online, and compared to flash storage such as FSx or VMware Flex, it’s vastly cheaper too in terms of £/TB.
Finally, the retention of data and ransomware protection. The SCFS is a log structured file system where all incoming data is written in encrypted form to new space with no over-writes, all recovery points are held as immutable snapshots which is neat given the increasingly common tactic of encrypting or compromising backups as part of a ransomware attack. The SCFS will hold [up to] 500,000 recovery points if you have the budget but given all backups are incremental, compressed and deduped it works out very cost effective. We can recover workloads from far back, including guest file system recovery, ie, individual files. There have also been recent additions to further help with ransomeware recovery and the product is rapidly gaining new features with each release.
Those who have read up on VCDR will know that protected VMs are replicated into what is ultimately an AWS S3 bucket, and if you know anything about S3 buckets you’ll know that compared to flash based storage they are cheap, and that they are slow. Buckets are not designed to run VMs from, they’re fine for static web sites, but anything with heavy IO and low latency requirement isn’t going to work very well. However VCDR is marketed as having near instant on abilities for recovered workloads, so how does the product achieve this? It does it by leveraging flash based storage in front of the S3 bucket to provide a caching layer if you will between it and the recovery SDDC. It does more, but I don’t want to give away all of its secrets. This way, VMs which are being recovered can benefit while we relocate them to the recovery SDDC’s WorkloadDatastore. This is done using regular Storage vMotion, as the SCFS is connected to the recovery SDDC as an NFS datastore.
With VCDR we can have a number of options for our recovery SDDC, depending on budget and requirements. We can have an on-demand option where the RTO requirement is a few hours. With this, the SDDC is deployed when we want to failover. The next option is a pilot light environment, where we only have a few nodes online however we can maintain an RTO of minutes, and in case of failover, we add more nodes as we start the recovery process. Then finally we have the gold plated solution where the recovery SDDC is sized for all of our protected VMs and we can have a near active/active solution.
There are some drawbacks to VCDR however. Currently, we can only protect on-premesis vSphere or a VMC/A SDDC (please check the documentation for version requirements). We can also only recover to a VMC/A environment. GCVE has recently gone into preview as a protected site, so things are changing. If you’re using AVS or other cloud infrastructure then watch this space.
If you have no interest in the public cloud, then it’s clear that VCDR will do very little for you and SRM would be a better fit. Just ensure that you have a well defined backup policy with immutability. Wheres if you already have a large public cloud presence, or you wish to explore it further, then VCDR may be worth pursuing.
There is of course a lot more to consider, such as networking and connectivity, but that is out of scope for this post. Also, SRM and VCDR particularly can do a lot more than I’ve covered, so please do check out the respective product documentation for more information.
There’s also a VMware blog covering each solution with a great comparison table toward the bottom.
Hopefully this provides a little more context if you are comparing the two products. I hope you’ve enjoyed reading and please leave a comment if you have any questions or queries.
Excellent comparison! Thanks Chris!