UPDATE 30th August 2024 – HCX 4.10 incorporates the upscaling scripts, please refer to this kb: https://knowledge.broadcom.com/external/article/373010
I’ll remove the script in this post, however will leave the rest for completeness.
At the time of writing, in its default configuration HCX will support up to 300 concurrent migrations per Manager, and 200 concurrent migrations per Service Mesh/IX Appliance. Whilst these numbers are high, there are scenarios where higher numbers are required. For example, if you have three Service Meshes, you are still constrained by the HCX Manager supporting 300 concurrent migrations which means you can’t use all three Service Meshes to their full potential. With the release of HCX 4.7 there is an option to upsize (or scale up) the HCX Manager to support parallel 600 migrations in total and the instructions are here – https://kb.vmware.com/s/article/93605
In short, the VM configuration is changed to 32 vCPU, 48GB RAM, and has an additional 300GB HDD. Post VM changes, there’s quite a bit of CLI involved and it can invariably lead to mistakes or potentially confusion. I figured I’d create a bash script to take care of the CLI steps.
Disclaimer: These steps or the script have not been verified internally, therefore I would advise caution and mention that it is likely not supported. However feel free to try it out in a lab environment ensuring to comment out the relevant checks if you don’t want to assign the resources. If you do run it without the increased resources you are likely to break the manager. You can always revert to snapshot in case of unexpected results.
Important: There are actually two parts of the script, the first part is only relevant when running this for the first time. The second part must be run on any existing manager that has this new configuration and has been upgraded, ie, from 4.7 to 4.9, run the second script at the end of this post.
First, shut the HCX manager down and change the VM configuration as per the kb (CPU, RAM, and add the 300GB HDD). Then take a snapshot. Power the VM on, put the below script in /home/admin or /tmp, switch to root, make it executable and then run. Post completion and checking everything is okay, don’t forget to remove the snapshot.
If you find it useful, please let me know in the comments below, and be sure to check back in case of any updates. Feedback is of course welcome.
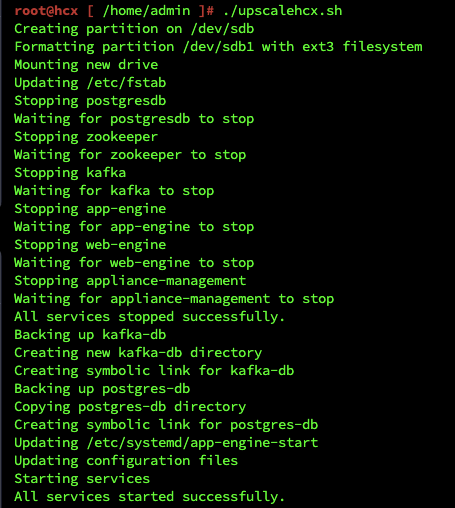
And a screenshot of it running in my lab:
And here is the script to run on an upgraded manager. There are no checks here, I will update.